Case 2: Migrating from Incremental to Incremental with Qualify
This guide shows how to migrate an incremental pipeline to incremental_with_qualify, which adds automatic primary-key deduplication.
Problem: incremental pipelines capture every version of a record, generating duplicates in the target.
Solution: migrate to incremental_with_qualify, which keeps only the most recent version of each record.
Authentication
import requests
import json
import os
from pprint import pprint
BASE_URL = "https://maestro.dadosfera.ai"
response = requests.post(
f"{BASE_URL}/auth/sign-in",
data=json.dumps({
"username": os.environ['DADOSFERA_USERNAME'],
"password": os.environ["DADOSFERA_PASSWORD"]
}),
headers={"Content-Type": "application/json"},
)
headers = {
"Authorization": response.json()['tokens']['accessToken'],
"Content-Type": "application/json"
}
Step 1: Identify the pipeline and job
We will use the same pipeline created in Case 1.
PIPELINE_ID = "7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae"
JOB_ID = "7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae-0"
response = requests.get(f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}", headers=headers)
job_config = response.json()
pprint(f"\nCurrent load_type: {job_config.get('source_config', {}).get('load_type')}")
pprint(f"primary_keys: {job_config.get('source_config', {}).get('primary_keys', 'NOT DEFINED')}")
'Current load_type: incremental'
'primary_keys: None'
Step 2: Migrate the sync mode
The POST /platform/jobs/jdbc/{jobId}/sync-mode endpoint performs the migration with full validation.
Required parameters:
target_load_type: the new sync mode.primary_keys: the columns that uniquely identify each record.incremental_column_nameandincremental_column_type: the incremental control column.
payload = {
"target_load_type": "incremental_with_qualify",
"incremental_column_name": "updated_at",
"incremental_column_type": "timestamp",
"primary_keys": ["id"]
}
response = requests.post(
f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}/sync-mode",
headers=headers,
json=payload
)
pprint(response.json())
{
"message": "Successfully migrated sync mode to incremental_with_qualify",
"migration_details": {
"state_action": "preserve",
"target_load_type": "incremental_with_qualify",
"warnings": []
},
"status": "success"
}
Step 3: Verify the change
The state_action: "preserve" value means that the incremental state was kept and the next execution will continue from the same point.
response = requests.get(f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}", headers=headers)
job_config = response.json()
print(f"load_type: {job_config.get('source_config', {}).get('load_type')}")
print(f"primary_keys: {job_config.get('source_config', {}).get('primary_keys')}")
load_type: incremental_with_qualify
primary_keys: ['id']
Step 4: Execute the pipeline
payload = {"pipeline_id": PIPELINE_ID}
response = requests.post(
f"{BASE_URL}/platform/pipeline/execute",
headers=headers,
json=payload
)
pprint(response.json())
Result
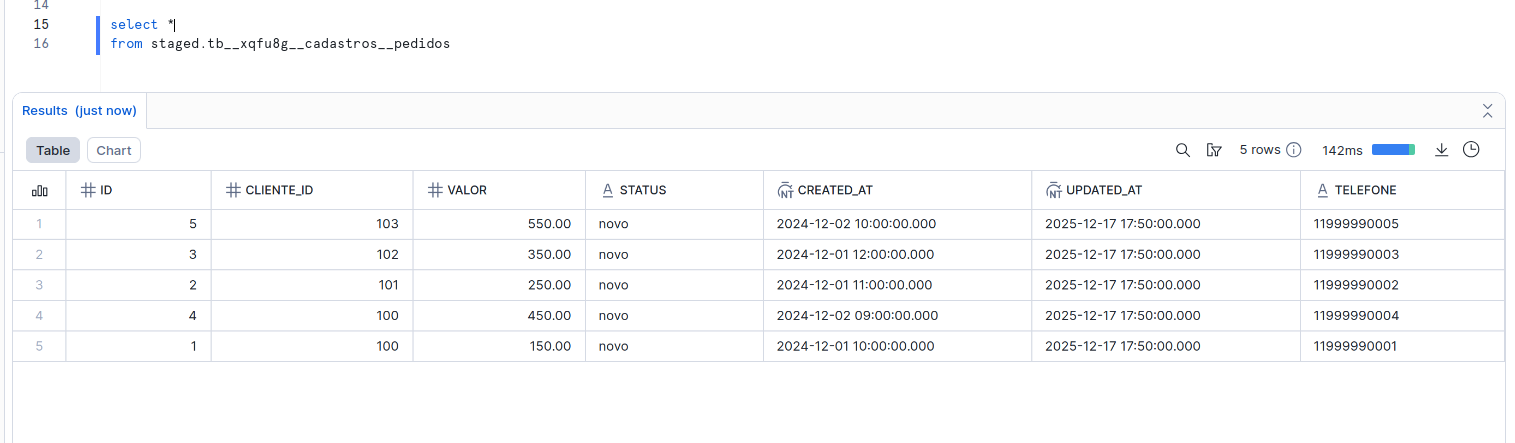
With incremental_with_qualify, a new table is created in the STAGED schema containing only the most recent version of each record. Both the schema and table names can be customized through the API.
Results:
- IDs are deduplicated, with only one record per
id. - The new
telefonecolumn is now present in the data.